Définition :
La fréquence d'échantillonnage \(f_e\) est le nombre d'instants sélectionnés par seconde pour prendre la mesure de l'amplitude du signal.
Si on note \(T_e\) la durée (en secondes) entre deux instants sélectionnés, on a \(f_e\times T_e=1\) donc \(f_e=\frac{1}{T_e}\).
Question⚓
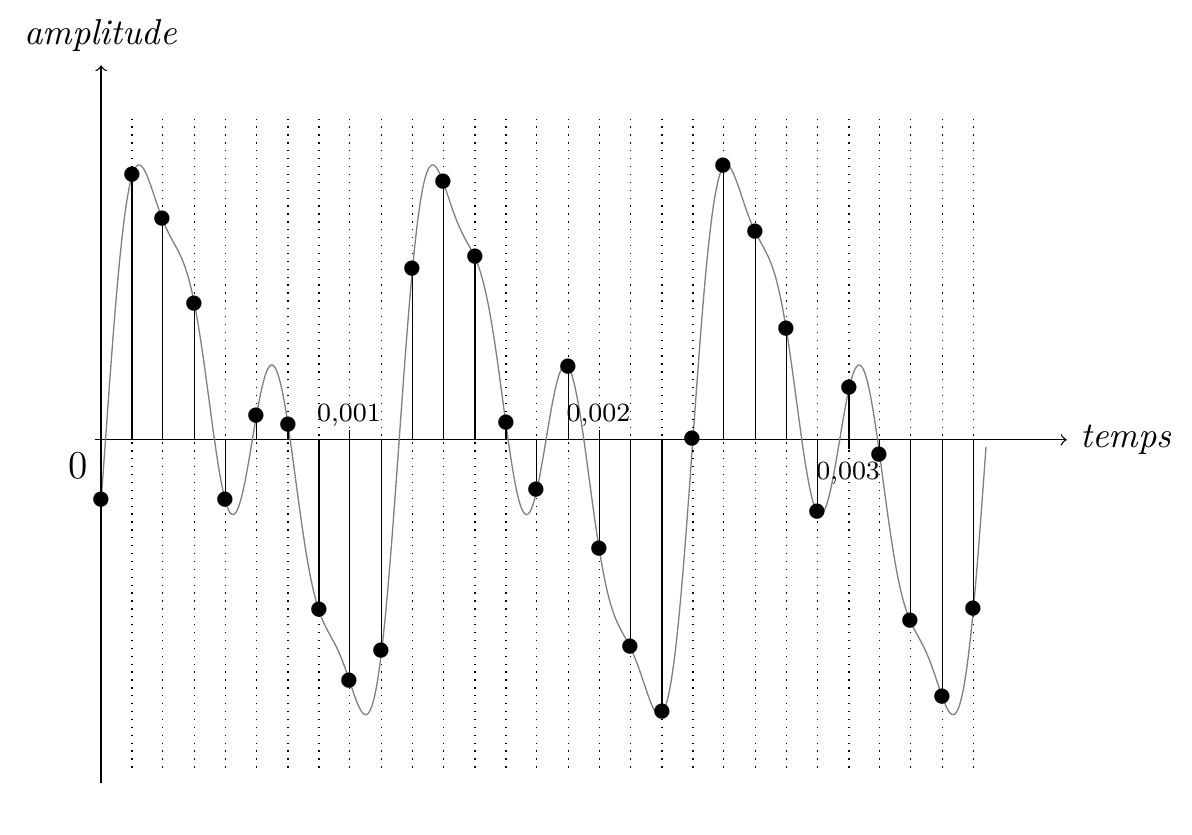
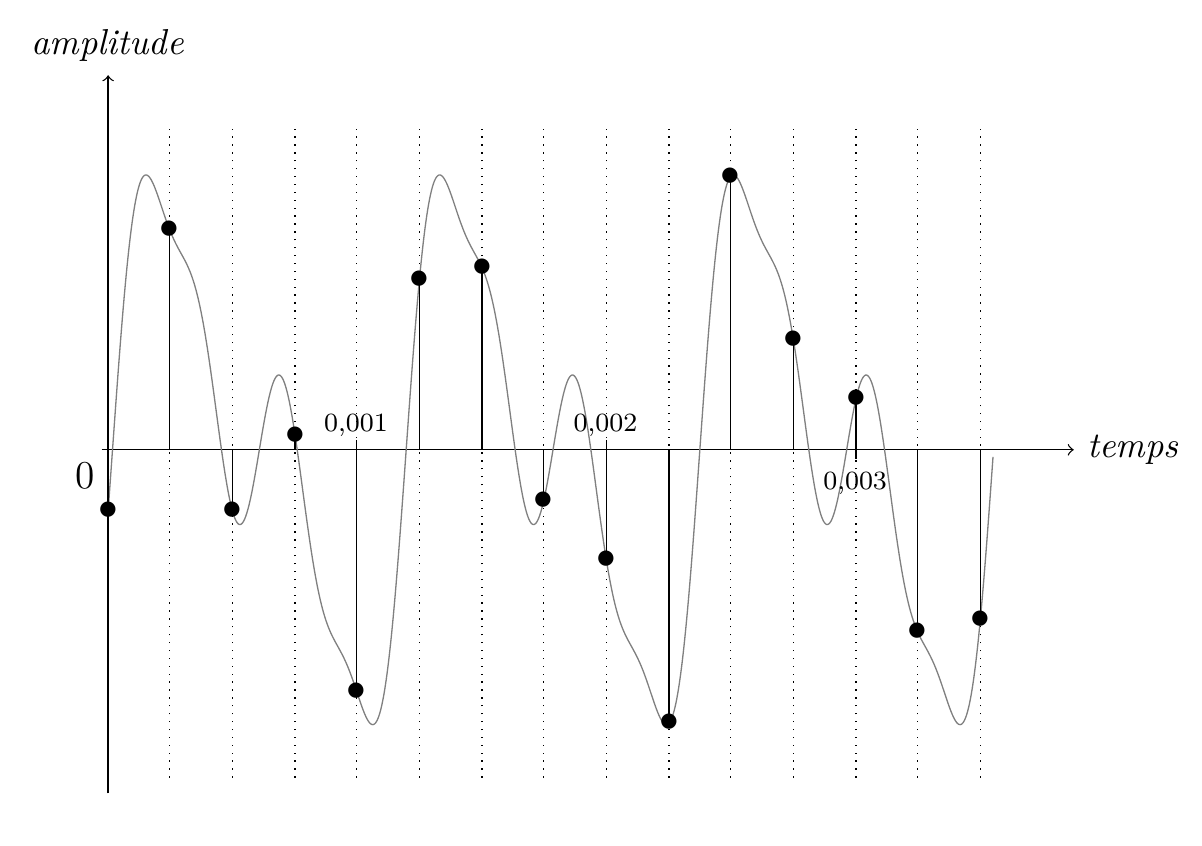
Quelle fréquence d'échantillonnage a été utilisée pour sélectionner des instants dans chacun des deux graphes ci-dessous ? L'unité de temps sur l'axe des abscisses est la seconde.
Solution⚓
Dans le premier graphe, on a sélectionné \(8\) instants dans chaque intervalle de \(0{,}001\) seconde, donc \(8\,000\) instants par seconde, la fréquence d'échantillonnage est donc \(8\,000\) Hz, c'est-à-dire \(8\) kHz.
Dans le second graphe, on a sélectionné \(4\) instants dans chaque intervalle de \(0{,}001\) seconde, deux fois moins que dans le premier ; la fréquence d'échantillonnage est donc la moitié de la précédente, c'est-à-dire \(4\) kHz.
On sent bien que, si on ne prend pas suffisamment de mesures du signal par seconde, c'est-à-dire si \(f_e\) est trop petite, par exemple si \(f_e\) est inférieure à la fréquence du signal, l'information qu'on obtiendra ne rendra pas bien compte du signal reçu. La théorie de l'information développée notamment par Shannon vers le milieu du XXe siècle permet de donner un sens précis à cette intuition. Le résultat à retenir est le suivant.
Attention : Théorème de Shannon
Pour pouvoir reconstituer le signal d'origine à partir de l'échantillonnage, il faut et il suffit que la fréquence d'échantillonnage soit au moins deux fois supérieure à la fréquence maximale contenue dans le signal à numériser.
Question⚓
L'oreille humaine entend les sons dont la fréquence est comprise entre \(20\) Hz et \(20\,000\) Hz. Quelle valeur minimale doit avoir la fréquence d'échantillonnage d'un système destiné à numériser convenablement les sons que nous pouvons entendre ?
Question⚓
La voix humaine produit des sons de fréquence comprise entre \(100\) et \(3\,400\) Hz, quelle valeur la fréquence d'échantillonnage d'un système téléphonique doit-elle avoir au minimum pour une transmission convenable ?
Exemple :
En pratique, on utilise souvent des fréquences d'échantillonnage légèrement plus grandes que le double de la fréquence maximale du signal :
Support | fréquence d'échantillonnage |
CD audio | \(44{,}1\) kHz |
DVD | \(48\) kHz |
Téléphone | \(8\) kHz |
Radio numérique | \(22{,}5\) kHz |
Question⚓
L'échantillonnage présenté dans les deux graphes ci-dessous permet-il de numériser convenablement le signal ?
Solution⚓
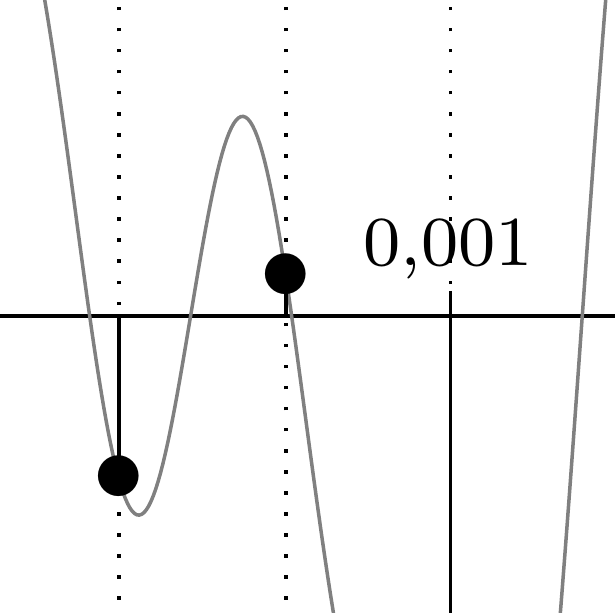
D'après le théorème de Shannon, on doit considérer la fréquence maximale du signal à numériser, c'est celle de la sinusoïde de plus petite amplitude qui apparaît dans les images ci-dessous, obtenues en zoomant dans chacun des deux graphiques aux environs de l'abscisse \(0{,}001\) :
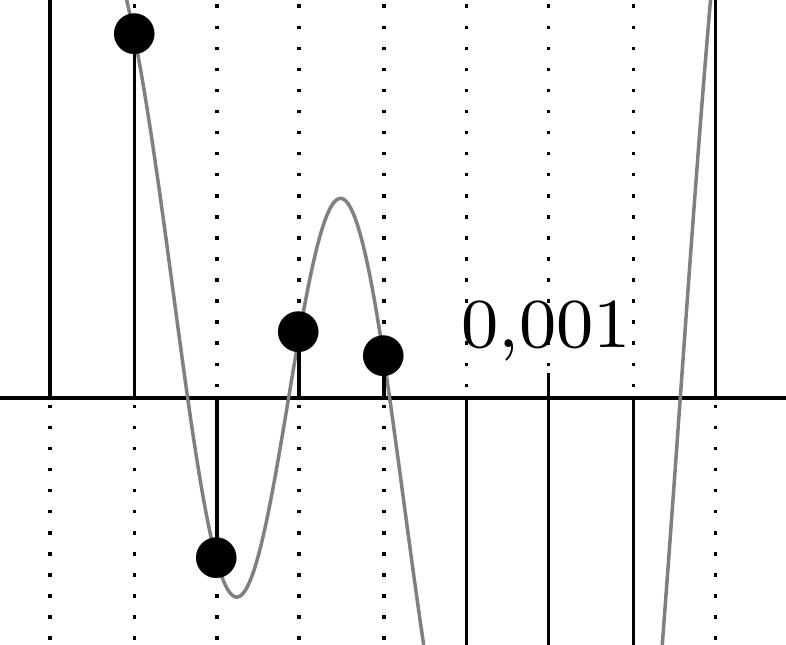
Dans le premier cas, l'écart \(T_e\) entre deux instants sélectionnés est inférieur à la moitié de la période \(T\) de la petite sinusoïde : \(T_e\le\frac{T}{2}\) ; en passant à l'inverse pour obtenir les fréquences, cela donne : \(f_e\ge2f\), la fréquence d'échantillonnage est supérieure au double de la fréquence maximale contenue dans le signal, qui est donc convenablement numérisé.
Dans le second cas, on voit sur l'image zoomée que l'écart \(T_e\) est nettement supérieur à la moitié de la période \(T\) (\(T_e\) semble même assez proche de \(T\)) ; en passant à l'inverse, on obtient \(f_e<2f\), la fréquence d'échantillonnage est strictement inférieure au double de la fréquence maximale contenue dans le signal, qui n'est donc pas convenablement numérisé.
Le théorème de Shannon donne une indication claire de la fréquence d'échantillonnage à utiliser : au moins le double de la fréquence maximale contenue dans le signal reçu. En pratique il faudra décider, comme dans le cas du téléphone ou du CD audio, de négliger les fréquences les plus hautes à partir d'un certain seuil (en particulier les fréquences inaudibles), en fonction de l'usage (numérisation fidèle de la voix ou d'une musique), de façon à ne pas stocker des valeurs d'échantillon inutiles. Chaque valeur à stocker prend en effet de la place en mémoire, comme on va le voir dans l'activité suivante.